Niveau : intermédiaire
ZFS existe sur de nombreux systèmes : sur OpenSolaris, sur FreeBSD, et depuis peu, officiellement sur Linux.
J'ai décidé d'installer ZFS sur FreeBSD, qui est bien plus mûr (version 28), bien que très légèrement en retard par rapport à la version OpenSolaris. C'est avant tout une question de choix personnel : j'aime bien FreeBSD !
Nous avons vu dans l'article précédent comment préparer le serveur Proliant :
Installation d'un serveur HP Proliant Microserver (partie 2/2)
J'ai aussi écrit un article présentant ZFS, ses avantages et ses défauts :
Introduction à ZFS
Pour résumer les épisodes précédents
Nous avons :
- 8GO de RAM
- un disque SSD de 64GO, qui servira pour le stockage des données système et pour le cache
- quatre disques de 3TO chacun
- deux cartes réseau
- je choisis d'attribuer l'adresse IP 192.168.0.3/24 au serveur
- je crée, sur le SSD, à l'installation de FreeBSD, une partition de 6,4GO pour le système (FreeBSD est très léger)
- et une autre de 60GO, qui me servira de cache L2ARC
Aujourd'hui, nous allons voir comment faire, avec ce matériel, un serveur de fichiers performant, grâce à ZFS.
Configuration du réseau
Vous avez installé le système de base, maintenant, passons à la configuration réseau.
Nous avons deux cartes réseau (une intégrée, et une carte Intel), que nous pouvons lier.
Si vous avez un switch manageable prenant en compte l'agrégation de liens (802.3ad ou encore LACP), il vaut mieux configurer le serveur via cette méthode. Tant que vous aurez les 2 liens qui fonctionneront, vous aurez la possibilité de doubler votre débit (je dis bien la possibilité, cela n'est pas garanti). Si l'un des liens tombe, vous continuerez sans que la panne ne se remarque au niveau réseau.
Si vous avez un switch standard, vous ne pourrez pas utiliser LACP. Il existe deux possibilités software que vous offre FreeBSD : "failover" ou "roundrobin".
La première permet d'avoir une interface active, et l'autre passive, mais qui prendra le relais si l'active tombe. Elle fonctionne très bien.
Pour avoir essayé la seconde, elle permet de répartir les données sur les deux interfaces, mais d'une façon différente du LACP. J'ai pu mesurer des débits incroyables, meilleurs que le LACP à vrai dire, mais sans comprendre quels étaient les mécanismes réseau qui permettaient d'obtenir ces résultats. Les débits entre FreeBSD et Linux étaient exceptionnels, mais anormalement bas entre FreeBSD et Windows. J'ai donc exclu cette méthode, puisque dans une entreprise, un serveur de fichier sert souvent des postes Windows. Et parce que ça m'embêtait terriblement d'utiliser, en terme d'effets de bord sur un réseau d'entreprise, une "bidouille" qui n'était documentée nulle part.
Si quelqu'un a des informations précises sur cette méthode, je suis toutefois preneur !
L'association se fait entre l'interface bge0 (carte Broadcom intégrée) et l'interface em0 (carte Intel), et elle fournit l'interface agrégée lagg0
Il faut éditer votre fichier /etc/rc.conf, et rajouter les lignes suivantes :
# Pour la méthode hardware LACP
cloned_interfaces="lagg0"
ifconfig_bge0="up"
ifconfig_em0="up"
ifconfig_lagg0="laggproto lacp laggport bge0 laggport em0"
ipv4_addrs_lagg0="192.168.0.3/24"
#Pour la méthode software "failover", remplacer "lacp" par "failover" =D
Dans le cas du LACP, il faut le configurer côté switch aussi. La manipulation dépend de sa marque et de son modèle, je ne la détaillerai donc pas. Je ferai prochainement un article sur les switches Cisco, toutefois.
Pour redémarrer le service réseau sur FreeBSD, il faut taper la ligne de commande suivante :
/etc/rc.d/netif restart
Vous pourrez constater que la configuration est maintenant prise en compte :
# ifconfig
em0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=219b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,TSO4,WOL_MAGIC>
ether 68:05:ca:0a:0c:26
inet6 fe80::6a05:caff:fe0a:c26%em0 prefixlen 64 scopeid 0x1
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
bge0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=c019b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,TSO4,VLAN_HWTSO,LINKSTATE>
ether 68:05:ca:0a:0c:26
inet6 fe80::ea39:35ff:fe2d:f1cd%bge0 prefixlen 64 scopeid 0x2
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
media: Ethernet autoselect (1000baseT <full-duplex>)
status: active
lagg0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> metric 0 mtu 1500
options=19b<RXCSUM,TXCSUM,VLAN_MTU,VLAN_HWTAGGING,VLAN_HWCSUM,TSO4>
ether 68:05:ca:0a:0c:26
inet 192.168.0.3 netmask 0xffffff00 broadcast 192.168.0.255
nd6 options=29<PERFORMNUD,IFDISABLED,AUTO_LINKLOCAL>
media: Ethernet autoselect
status: active
laggproto lacp
laggport: bge0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
laggport: em0 flags=1c<ACTIVE,COLLECTING,DISTRIBUTING>
Nous allons procéder à quelques tunings réseau. Il faut pour cela éditer le fichier /etc/sysctl.conf, et rajouter les lignes suivantes :
net.inet.tcp.sendbuf_max=16777216
net.inetnet.inet.tcp.sendspace=65536
net.inet.tcp.sendspace=65536
net.inet.tcp.recvspace=131072
vfs.ufs.dirhash_maxmem=16777216
Et voilà, le réseau est opérationnel !
Tunings système
ZFS est installé de base, mais il faut faire quelques réglages, avant d'activer ZFS.
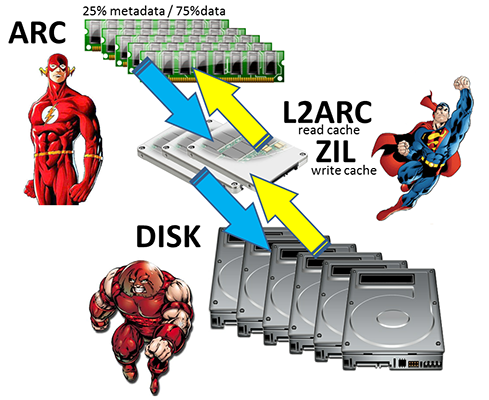
Nous avons sur le serveur 8GO de RAM, nous décidons d'en dédier 6 pour ARC.
Dans mon cas, j'ai désactivé ZIL, puisque les traitements lourds en terme d'écriture (logs, bases de données) se font surtout en local, via des SSD attachés à mes serveurs. Je n'en ai donc pas vraiment besoin.
De plus, je n'ai pas le budget pour le placer sur un SSD de bonne qualité, SLC. Si vous ne pouvez pas placer ZIL sur un SSD robuste, il vaut mieux ne pas l'utiliser, comme moi.
AIO est un module kernel essentiel pour la mise en œuvre d'un serveur, puisqu'il permet l'asynchronisme des entrées/sorties, et donc les opérations E/S non bloquantes (Asynchronous Input Output)
Editer le fichier /boot/loader.conf :
kern.maxfiles="20480"
aio_load="YES"
vfs.zfs.zil_disable="1"
vm.kmem_size="8192M"
vfs.zfs.arc_max="6144M"
#Chez moi, cette valeur marche mieux, bien que l'on recommande le contraire
vfs.zfs.prefetch_disable="0"
vfs.zfs.txg.timeout="5"
kern.maxvnodes=250000
vfs.ufs.dirhash_maxmem=16777216
vfs.zfs.l2arc_noprefetch=0
vfs.zfs.l2arc_write_max=250000000
vfs.zfs.l2arc_write_boost=350000000
Vous devez démarrer le module aio, via la commande suivante :
kldload aio
Activation du service ZFS
Demander au système de faire une vérification quotidienne du service ZFS :
echo 'daily_status_zfs_enable="YES"' >> /etc/periodic.conf
Taper la ligne de commande pour activer ZFS au démarrage :
echo 'zfs_enable="YES"' >> /etc/rc.conf
Démarrer le service ZFS :
/etc/rc.d/zfs start
Taper la commande kldstat pour vérifier que le module zfs.ko est chargé, ainsi que aio.ko
Ajout d'un utilisateur NFS pour l'ensemble du réseau
Il faut un utilisateur Unix que vous utiliserez sur l'ensemble du réseau, sur les montages NFS.
D'abord, sur le serveur FreeBSD, nous verrons le reste par la suite.
Choisir un nom, un groupe, ainsi que les UID et GID.
Dans mon cas, j'ai choisi "mydata" pour le nom et le groupe, 1002 pour le UID et GID.
Attention, les UID et GID correspondant à mydata doivent exister et être également configurés sur toutes les machines, c'est sur ces numéros que se fondent réellement les échanges NFS et SMB, les noms étant avant tout "cosmétiques".
... Toutefois, l'administrateur utilise les noms littéraux, beaucoup plus pratiques.
Si les numéros ou noms ne correspondent pas, vous aurez droit à une très pénible séance de débuggage!
Si vous avez du mal à faire l'inventaire de toutes vos machines, choisissez un UID et GID suffisamment haut pour être sûr qu'il n'est assigné nulle part, 4242 par exemple ?
Notez aussi le mot de passe que vous choisirez pour mydata, il vous servira pour vous connecter à partir des différents clients.
pw groupadd mydata -g 1002
pw useradd -n mydata -u 1002 -g 1002 -s /usr/sbin/nologin -d /mydata
passwd mydata
Création de la grappe ZFS
J'ai un disque dur en SSD, ada0, positionné en premier, et quatre disques durs mécaniques de 3TO, ada1 à ada4.
La partition servant au cache sera la 4e du SSD, ada0p4.
Il n'y a qu'une partition pour les quatre disques de stockage.
Je crée la grappe ZFS :
zpool create mydata raidz ada1 ada2 ada3 ada4
chown mydata:mydata /mydata
Je choisis de ne pas gérer le "atime" (access time) dessus.
En effet, à chaque fois qu'un fichier sera lu, l'attribut "atime" est modifié, pour refléter l'heure et la date du dernier accès. Ca nous fait une écriture à chaque fichier lu, et c'est inutile.
Le atime peut servir dans un contexte de sécurité, mais il est probable qu'il ne vous sera jamais utile, autant avoir un gain de performances, sauf si vous avez des exigences de sécurité très précises.
zfs set atime=off mydata
Vous pouvez vérifier que tout s'est bien passé via les commandes suivantes :
# zpool status -v mydata
pool: mydata
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mydata ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
ada3 ONLINE 0 0 0
ada4 ONLINE 0 0 0
errors: No known data errors
# zpool list
NAME SIZE ALLOC FREE CAP DEDUP HEALTH ALTROOT
mydata 10.9T 169K 10.9T 0% 1.00x ONLINE -
Maintenant, rajoutons le L2ARC à la grappe ZFS.
Notez l'alignement 4K des secteurs, afin que les performances soient maximales, les SSD récents ayant tous des secteurs de 4KO.
gpart add -t freebsd-zfs -a 4k -l l2arc0 ada0
zpool add mydata cache ada0p4
# zpool status -v mydata
pool: mydata
state: ONLINE
scan: none requested
config:
NAME STATE READ WRITE CKSUM
mydata ONLINE 0 0 0
raidz1-0 ONLINE 0 0 0
ada1 ONLINE 0 0 0
ada2 ONLINE 0 0 0
ada3 ONLINE 0 0 0
ada4 ONLINE 0 0 0
cache
ada0p4 ONLINE 0 0 0
errors: No known data errors
Activation du NFS
Pour activer le service NFS au démarrage de la machine, éditer /etc/rc.conf
rpcbind_enable="YES"
nfs_server_enable="YES"
mountd_flags="-r"
Et puis lancer les services, pour cette fois-ci :
/etc/rc.d/rpcbind start
/etc/rc.d/nfsd start
Il est nécessaire de préciser à NFS pour quelles adresses IP on autorise l'accès (ici 192.168.0.0/24)
Ce que l'on appelle les "exports".
Normalement, il faut éditer le fichier /etc/exports
Toutefois, nous allons utiliser NFS via les commandes ZFS, ce service étant capable de gérer le daemon NFS.
Les données que vous indiquerez iront dans /etc/zfs/exports, mais je vous conseille de ne jamais éditer ce fichier à la main, comme vous avez l'habitude de le faire pour NFS en mode autonome !
zfs set sharenfs="-mapall=mydata -alldirs -network 192.168.0.0 -mask 255.255.255.0" mydata
Si vous deviez par hasard interrompre le service NFS, pour une maintenance par exemple :
zfs set sharenfs=off mydata
Activation de SAMBA
La version de Samba livrée avec FreeBSD 9.0, la stable de l'époque, était quelque peu défectueuse (Unsupported share protocol: 1).
Il m'a donc fallu mettre à jour la distribution.
Je dois avouer qu'autant le processeur ne m'a jamais déçu pour servir les fichiers (je ne l'ai jamais vu monter à plus de 20% en deux ans), autant il se montre "léger" pour compiler. Néanmoins, c'est comme cela que j'ai installé la dernière version de Samba :
freebsd-update fetch
freebsd-update install
cd /usr/ports/net/samba36
make install clean
(il faut sélectionner impérativement le support "AIO" !!!)
Configurer le serveur pour que SAMBA soit activé au démarrage :
echo 'samba_enable="YES"' >> /etc/rc.conf
Modifions le service, en éditant le fichier /usr/local/etc/smb.conf :
[global]
#Quelques tunings système
socket options = TCP_NODELAY SO_SNDBUF=131072 SO_RCVBUF=131072
use sendfile = no
min receivefile size = 16384
aio read size = 16384
aio write size = 16384
aio write behind = yes
max protocol = smb2
workgroup = WORKGROUP
server string = Cthulhu
security = user
# J'autorise tout comme pour NFS, le réseau 192.168.0.0/24 à accéder aux partages
hosts allow = 192.168.0.
encrypt passwords = yes
load printers = no
#Le partage que j'ai crée. Vous pouvez vous en inspirer pour créer les vôtres
[mydatasmb]
path = /mydata
unix extensions = no
writable = yes
valid users = mydata
create mask = 0775
nfs4:mode = special
nfs4:acedup = merge
nfs4:chown = yes
Samba se sert d'utilisateurs internes, et non pas des utilisateurs Unix classiques.
Il faut donc ajouter un utilisateur "mydata" au service :
smbpasswd -a mydata
Et entrer le mot de passe que vous avez choisi pour l'utilisateur mydata.
Redémarrer le service SAMBA pour prendre en compte les changements.
/usr/local/etc/rc.d/samba restart
Se connecter aux partages à partir d'un poste Windows
Le client NFS de Windows est très mal écrit (vraiment).
Pour que le NFS marche convenablement sur Windows, il faut modifier sa base de registre.
Et vous ne pourrez non plus accéder au partage SAMBA à partir d'un Windows moderne, sans modifications.
Ce n'est pas une limitation due à FreeBSD ou ZFS.
C'est une limitation de toutes les versions de SAMBA actuelles, y compris sous Linux.
En effet, Microsoft ne documente pas le protocole SMB (les joies du logiciel propriétaire !), et les auteurs de SAMBA doivent donc trouver comment il marche par "reverse engineering", ce qui prend énormément de temps.
Ce qui fait que le service SAMBA aura toujours un "train de retard" par rapport aux serveurs de fichiers Windows, pour ce protocole du moins.
Il y a donc des options de sécurité à débloquer sur les Windows 7 et 8, afin de rendre l'accès réseau compatible avec les versions des protocoles SMB "obsolètes"
Je décris les procédures d'accès NFS et SAMBA, à partir de Windows, dans l'article suivant :
Accéder à des partages NFS et SAMBA depuis Windows Vista 7 et 8
Quelques commandes utiles pour tester et benchmarker
Monter le partage NFS à partir d'un Linux
Le montage sera interruptible (intr), n'utilisera pas le verrouillage de fichiers NFS (nolock), et n'essaiera pas de modifier les dates d'accès pour les fichiers ni les répertoires.
Sur de petits fichiers, cela doublera pratiquement les débits !
addgroup --gid 1002 mydata
adduser --home /nfs --shell /bin/false --ingroup mydata mydata
chown mydata:mydata /nfs
Editer /etc/fstab, et ajouter la ligne, pour que le répertoire distant soit monté au boot :
192.168.0.3:/mydata /nfs nfs noatime,nodiratime,nolock,intr,timeo=20,rw 0 0
Il ne reste plus qu'à monter le répertoire distant :
mount /nfs
Monitorer en live les débits
Au début de l'article, nous avions crée une agrégation entre les deux cartes réseau, qui s'appelle lagg0.
La commande iftop devrait faire partie de la boîte à outils de tout administrateur :
iftop -i lagg0
Mesurer les perfomances de la grappe raid
Un logiciel formidable pour cette tâche : "iozone". Il permet de simuler l'écriture d'un fichier, tout en s'affranchissant du besoin de faire une copie, depuis le réseau ou une autre grappe, par exemple.
Ce qui permet d'effectuer des mesures sur les performances d'un disque dur ou d'une grappe en local, sans qu'elles ne soient parasitées par des facteurs externes.
Il faut d'abord se positionner sur le répertoire de la grappe à benchmarker.
Le paramètre -i permet de spécifier le type de test (0 pour l'écriture, 1 pour la lecture), ici nous avons une écriture, suivie d'une lecture.
Il faut que le fichier soit écrit avant de pouvoir être lu, bien sûr.
-t spécifie qu'il y a aura 2 threads qui écriront en parallèle, puisque le processeur a deux cores
-F spécifie le nombre de fichiers, ici iozonetest1 et iozonetest2 (à chaque thread, son fichier)
-r spécifie la taille des blocs en KO, ici 1024KO, soit 1MO.
-s spécifie la taille de CHAQUE fichier, ici 16GO, soit 32GO avec deux threads.
Bien-sûr, plus la taille des fichiers sera grande, plus les mesures seront justes, puisque le cache système, trop petit pour une grande quantité de données, n'influencera pas les résultats.
Vu que nous générons 32GO de données, le test va mettre plusieurs minutes à s'exécuter.
# iozone -i 0 -i 1 -t 2 -F iozonetest1 iozonetest2 -r 1024 -s 16g
Record Size 1024 KB
File size set to 16777216 KB
Command line used: iozone -i 0 -i 1 -t 2 -F iozonetest1 iozonetest2 -r 1024 -s 16g
Output is in Kbytes/sec
Time Resolution = 0.000001 seconds.
Processor cache size set to 1024 Kbytes.
Processor cache line size set to 32 bytes.
File stride size set to 17 * record size.
Throughput test with 2 processes
Each process writes a 16777216 Kbyte file in 1024 Kbyte records
Children see throughput for 2 initial writers = 197361.69 KB/sec
Parent sees throughput for 2 initial writers = 190827.57 KB/sec
Min throughput per process = 98390.77 KB/sec
Max throughput per process = 98970.92 KB/sec
Avg throughput per process = 98680.84 KB/sec
Min xfer = 16678912.00 KB
Children see throughput for 2 rewriters = 207404.59 KB/sec
Parent sees throughput for 2 rewriters = 197795.23 KB/sec
Min throughput per process = 102760.07 KB/sec
Max throughput per process = 104644.52 KB/sec
Avg throughput per process = 103702.29 KB/sec
Min xfer = 16475136.00 KB
Children see throughput for 2 readers = 339691.28 KB/sec
Parent sees throughput for 2 readers = 339679.90 KB/sec
Min throughput per process = 164756.38 KB/sec
Max throughput per process = 174934.91 KB/sec
Avg throughput per process = 169845.64 KB/sec
Min xfer = 15801344.00 KB
Children see throughput for 2 re-readers = 335127.98 KB/sec
Parent sees throughput for 2 re-readers = 335117.32 KB/sec
Min throughput per process = 165701.81 KB/sec
Max throughput per process = 169426.17 KB/sec
Avg throughput per process = 167563.99 KB/sec
Min xfer = 16408576.00 KB
Les résultats obtenus sont, je trouve, plutôt impressionnants, vu le prix ridicule de la machine que nous avons mis en place : 196,3 MO/s en écriture, 339,7 MO/s en lecture !!!
Partager l'article



 Milosz SZOT est ingénieur systèmes & réseaux spécialisé dans Linux et l'hébergement de sites web à fort trafic.
Milosz SZOT est ingénieur systèmes & réseaux spécialisé dans Linux et l'hébergement de sites web à fort trafic.