
Niveau : intermédiaire
Dans les précédents articles, j'avais expliqué comment installer un serveur de stockage ZFS, quelques optimisations de base pour ESXi et quelques best practices.
Toutefois, le sujet est très vaste, et nous n'en sommes qu'à la "prise de contact" : le niveau de connaissances exigé pour gérer ne serait-ce qu'une petite structure virtuelle est assez élevé ...
Ce que je vous propose donc, c'est de poursuivre l'initiation en nous intéressant aux performances NFS et à une architecture "classique" pour ESXi et le stockage réseau.
Dans le premier article de la série, j'ai choisi un serveur de stockage pour mon lab, le plus performant possible pour sa catégorie, mais surtout pas cher, et doté d'une capacité de stockage importante.
Installation d'un serveur HP Proliant Microserver (partie 1/2)
Dans le second, j'avais expliqué comment configurer un serveur de stockage ZFS :
Installation d'un serveur de fichiers ZFS sous FreeBSD
Enfin, je me suis intéressé au fonctionnement de NFS dans ESXi, aux limitations de l'implémentation du protocole, et à une solution de dépannage "convenable" pour un lab
Mauvaises performances ESXi et ZFS - NFS
Maintenant que nous avons un stockage en réseau correct, nous allons voir quelle est l'architecture adaptée pour un lab ESXi et quels sont les tunings possibles.
Architecture matérielle
Séparation des trafics selon leur nature
Si vous pouvez vous permettre des cartes réseaux et des switches 10 Gbps Ethernet sur votre infrastructure de production, vous pourrez mettre en place une infrastructure réseau "convergée", dans lequel le trafic VM est mélangé avec le trafic stockage, qu'il soit NFS ou iSCSI.
Toutefois, VMware déconseille fortement de mélanger le trafic "administratif" avec le trafic VM, qui plus est, sur une architecture traditionnelle 1 Gbps.
J'entends, par trafic administratif, toutes les connexions nécessaires au bon fonctionnement d'ESXi et de vSphere, en interne : stockage réseau des images VM, mais aussi la console de management et vmotion.
Je vois quatre raisons principales qui motivent cette recommandation :
- La sécurité, puisque le trafic NFS et vMotion transite sans être crypté. Si un attaquant réussit à prendre le contrôle d'une VM, il pourra potentiellement sniffer toutes les données NFS / vMotion qui passent par l'hôte ESXi
- L'isolation des performances, puisque la limite des 1 Gbps peut être rapidement franchie, et que le trafic "administratif" peut potentiellement étouffer le trafic "VMs", et vice et versa
- Le cloisonnement des broadcasts sur leurs réseaux respectifs
- En séparant les trafics, il est plus facile de les contrôler et de leur fixer des limites individuelles
Dans le cadre d'une infrastructure de production 1 Gbps, il est donc conseillé d'avoir des cartes réseaux séparées pour les VMs, le stockage, et le vmotion / management.
Idéalement, cela nous ferait 3 voire 4 ports 1 Gbps par hôte, et comme ils doivent être redondés, il faut doubler le nombre de ports, soit 6 ou 8 ports au total.
Il existe heureusement des cartes PCI Express 2 ou 4 ports, qui permettent cette densité.
Dans une infrastructure de production 10 Gbps, nous pouvons envisager plus sereinement de mixer le trafic VM et administratif, sans trop craindre pour les performances.
Bien que d'un point de vue sécurité, il soit toujours recommandé d'isoler trafics VM et administratif.
Pour résumer, cela revient à 2 voire 4 ports 10 Gbps au total (il ne faut pas oublier la redondance), selon les moyens financiers à disposition et la qualité visée par l'infrastructure.
Pour une infrastructure de type "lab", qui permet de découvrir, de se former, de tester de nouvelles fonctionnalités, il est peu probable que votre management soit prêt à dépenser 20 ou 30 k€ ;-)
Nous partons donc sur une infrastructure 1 Gbps !
Puisque mes moyens à moi sont limités, j'ai donc une infrastructure "de base", avec :
- un voire deux hôtes ESXi (voir la section "nested ESXi", plus bas)
- 2 ports gigabit par hôte
- en agrégation de liens (Etherchannel chez Cisco)
- un switch Cisco SG300-10, qui est un SPOF (Single Point of Failure)
- qui est un switch administrable de niveau 3 (gère le load balancing sur la couche IP ou la couche Ethernet), compatible LACP (802.3ad), VLANs (802.1Q), ainsi que "Jumbo Frames" (les MTU supérieures à 1500 octets)
- un filer, pour le moment non-redondant aussi, le HP Proliant Microserver, avec deux ports gigabit configurés en LACP (voir cet article)
Je sais déjà utiliser des switches stackables (plusieurs switches physiques qui sont vus comme un seul), et faire des serveurs de stockage hautement disponibles.
Il est important d'avoir ces connaissances-là, mais elles ne sont pas essentielles pour l'apprentissage de la virtualisation via ESXi / vSphere, elles sont complémentaires, et peuvent être apprises sur d'autres projets.
Donc j'ai décidé de me passer de ces redondances, afin d'économiser beaucoup d'argent sur la mise en place de mon lab.
Séparation par VLANs
Puisque mes moyens ne me permettent pas de séparer physiquement les trafics de nature différente, je vais me contenter de les séparer logiciellement, via les VLANs.
S'ils me permettent d'avoir un certain niveau de sécurité, les VLANs ne me prémuniront pas des problèmes de saturation : le trafic du stockage et vmotion pourront saturer le réseau, et donc dégrader les performances du trafic VMs voire de la console de management !
C'est un risque à prendre, mais nous sommes dans un environnement très contrôlé, le lab : la sécurité peut être abaissée, puisqu'il n'y a aucune donnée de production, et l'infrastructure peut "planter".
Et un certain nombre de dispositifs logiciels supplémentaires peuvent être mis en place pour éviter les risques d'étouffement (formation du trafic, "traffic shaping" en anglais, ou parts, "shares" en anglais)
J'ai décidé de placer le trafic stockage (NFS) sur le VLAN 3.
Le VLAN 2 sera dédié à la console de management, et le VLAN 4 à vMotion.
Hôtes physiques séparés ou Nested ESXi ?
L'idéal, c'est bien-sûr d'avoir deux machines physiques, pour pouvoir tester des scénarios intéressants sur vSphere, dans des conditions assez proches de la production.
Il reste toutefois une possibilité de tester les fonctionnalités de vSphere sur un seul hôte physique : nested ESXi ou hôtes ESXi imbriqués !
Sur une machine physique, nous installons un ESXi, dans lequel nous créons plusieurs machines virtuelles, qui seront elles-même hôtes ESXi.
Nous pouvons ainsi créer un certain nombre d'hôtes virtuels, pour les fonctionnalités liées à vSphere / Virtual Center, comme la haute disponibilité, le vmotion, etc.
Le réseau physique ne servira alors qu'à fournir les flux NFS.
Une bonne partie de l'infrastructure réseau, celle dont se servira vSphere, sera à 100% virtuelle, puisque le dialogue aura principalement lieu entre les hôtes virtuels (les VMs de niveau 1).
Attention toutefois, si la solution est économique, elle a toutefois un coût en ressources, notamment en RAM : une instance de vCenter demande dans les 6 GO de RAM à elle toute seule.
La solution demande alors rien que 8GO de RAM avec quelques optimisations hôte, sans les nested ESXi, ni les machines virtuelles.
Si nous déployons aussi des machines virtuelles "utiles" et fonctionnelles, qui ne soient pas autre chose que des réceptacles vides, il faut au minimum avoir 16, 24 voire 32 GO de RAM, selon vos besoins propres.
A ce moment-là, nous aurons des machines dont le comportement sera intéressant à étudier, qui permettront non seulement de tester vSphere, mais aussi tout ce qu'il est possible de faire avec un grand nombre de machines !
Haute disponibilité Linux / Windows , services http, SQL, déploiement automatique, Puppet, Chef, CfEngine, etc.
Bien-sûr, l'hôte n'en sera pas plus disponible pour autant, et s'il plante, toute l'infrastructure sera hors service.
Mais ce choix d'architecture permet d'avancer beaucoup plus loin, si pour une raison ou pour une autre, vous n'aviez qu'un seul serveur disponible.
Le jour où vous ferez l'acquisition d'un second serveur, il suffira d'ajouter le nouvel hôte au vCenter déjà existant, de migrer "en live" les VMs sur celui-ci, puis de réinstaller le premier serveur.
Pour la mise en place de Nested ESXi, je vous recommande la version 5 de vSphere au minimum.
Quelques réglages sur l'article suivant :
How to Enable Nested vFT (virtual Fault Tolerance) in vSphere 5
| Attention ! Pour faire du Nested ESXi, il faut également que les processeurs aient les jeux d'instructions EPT (Intel) ou RVI (AMD) ! Si les processeurs ne les ont pas, il n'est pas possible d'utiliser des VMs 64 bits à l'intérieur d'un Nested ESXi, sur les versions 5.X de vSphere. Ce qui en limite très fortement l'intérêt, puisque vCenter est 64 bits, par exemple ! Il vaut mieux dans ce cas-là, laisser tomber ... Mes processeurs par exemple, ne supportent pas EPT, ils sont trop vieux (2 x Xeon E5320) |
Convention de nommage des datastores
Il est bien évident que les datastores réseau doivent avoir le même nom et les mêmes propriétés sur les différents hôtes.
Sinon, toutes les fonctions réseau entre les hôtes échoueront, comme par exemple vMotion.
Il est parfois utile de créer un datastore local à un hôte.
Pour pouvoir s'y retrouver, au niveau global, mieux vaut alors décider d'une convention de nommage, qui sera respectée.
A noter que dans les versions 5.X d'ESXi, les points dans les noms des datastores ne posent plus de problème, ni dans vSphere, ni dans les outils tiers, tels que GhettoVCB.
Dans mon cas, pour un datastore distant, c'est typedemontage+nommachine (j'ai un point de montage pour chaque VM !)
Par exemple : nfs_lb1.milonz.fr
Pour un datastore local, c'est nomhôte+typedegrappe
Par exemple : esx1.milonz.fr.ssd ou esx1.milonz.fr.slowraid
Le MTU et ESXi
Le MTU, ou encore Maximum Transmission Unit est la taille maximum d'un segment transmis sans qu'il ne soit fragmenté.
La notion de MTU se retrouve sur chaque type de réseau.
Quelques valeurs typiques :
pour ethernet : 1500 octets
pour l'ADSL : 1468 octets
pour PPPoE : 1492 octets
pour l'IP, cela dépend du programme, mais la taille maximum du paquet est de 64KO
Pour ESXi, nous allons utiliser NFS par dessus TCP/IP par dessus Ethernet.
Le NFS servira à stocker les disques durs des machines virtuelles, et chaque opération de lecture et d'écriture se fera sur un bloc de taille importante.
Je n'ai pas l'information pour le paramétrage spécifique de vSphere puisqu'on ne peut pas tuner NFS de manière fine comme sur les Linux, mais les valeurs NFS classiques pour rsize et wsize sont de 8 KO, et on peut les augmenter jusqu'à 32KO.
Nous avons vu que pour Ethernet, quelle que soit la vitesse de la liaison, que ça soit 10 Mbps ou 1 Gbps, les trames sont fragmentées en blocs de 1500 octets.
Ce qui veut dire qu'une E/S NFS (rsize = 8KO) est encapsulée dans un paquet IP, qui sera fragmenté en 6 trames Ethernet.
Donc une E/S NFS fera 6 E/S sur le réseau Ethernet, chacune des trames ayant sa propre latence.
Si nous augmentons la valeur MTU, nous pourrons faire transiter des trames Ethernet plus grosses et plus adaptées à la nature du trafic NFS, donc nous gagnerons un peu de débit, puisque l'on aura diminué la fragmentation.
Lorsque la taille du MTU Ethernet dépasse les 1500 octets standard, nous parlons de "Jumbo Frames".
Chaque équipement réseau doit être compatible Jumbo Frames, sinon la trame Ethernet sera considérée comme invalide et rejetée.
Pour compliquer les choses, la valeur standard étant à 1500 octets, la valeur maximum admissible pour le MTU n'est pas standardisée, et varie selon les équipements réseau.
Pour certains, c'est 7-8KO, pour d'autres 9KO, voire 11-12KO pour certains.
La valeur optimale pour le MTU est donc la plus grande valeur que pourront supporter tous les équipements que vont traverser les trames Ethernet.
Il convient alors de vérifier la taille maximum du MTU pour les cartes réseau des ESXi, pour les switches, ainsi que pour les cartes réseau du serveur de stockage !
De plus, les drivers et l'OS spécifiquement utilisés doivent être capables de modifier le paramètre MTU Ethernet, ce qui n'est pas toujours le cas.
Le MTU maximum doit être explicitement paramétré sur chacun des équipements.
Pour vérifier le MTU effectif, nous avons 2 outils efficaces :
ifconfig
et
ping -d -s tailletrame ipdestination
En procédant de manière empirique, nous pouvons facilement déterminer le MTU optimal pour le réseau.
Si le MTU est admissible par le réseau, il y aura une réponse au ping, et cela voudra dire que l'équipement contacté aura reçu la requête, et qu'elle n'aura pas été droppée par l'un des équipements.
S'il n'y a pas de réponse au ping, cela voudra dire que l'un des équipements aura droppé la requête.
It's witchcraft !
Sur vSphere 5.X, utiliser les Jumbo Frames n'apporte pas automatiquement de gains, et elle ajoute un degré de complexité à votre réseau.
Ce n'est donc pas une recommandation à suivre aveuglément, elle demande à être évaluée précisément, individuellement.
En effet, VMware a fait énormément d'efforts pour optimiser les performances NFS "out of the box", avec un MTU de 1500 octets.
De plus, si d'un point de vue théorique, mathématique, les Jumbo Frames sont un avantage indiscutable, les gains réels dépendront surtout de votre infrastructure.
Les Jumbo Frames permettent d'optimiser les latences, les "temps morts" des transferts, ce qui a un effet bénéfique indirect sur la bande passante effective.
Mais le transfert de trames plus longues sur le réseau induit aussi des traitements plus longs par les équipements traversés.
Les gains réels dépendront donc de la qualité des ASIC (Application-Specific Integrated Circuit) des équipements réseau, des cartes PCI, des switches.
Bref, des capacités de traitement de l'infrastructure !
C'est pour cela que l'implémentation des Jumbo Frames ne doit jamais être automatique, mais qu'elle doit être évaluée de manière précise, pour chaque réseau.
Le réglage peut être très utile chez un client A, et peut très bien être inutile voire contre-productif chez un client B ...
Chaque modèle de carte réseau doit être testé (capacités d'offload), ainsi que chaque modèle de switch.
Nature des montages NFS
C'est certainement le paramétrage le plus important et crucial, et c'est une règle d'or, valable pour ESXi, mais aussi pour toute utilisation de NFS, de manière générale.
Si vous utilisez un seul montage NFS, les débits seront "mous", inférieurs à ce que vous pouvez espérer.
Pour maximiser les débits, il faut utiliser plusieurs connexions.
Nous avons vu dans un article précédent que ESXi utilisait les montages NFS en mode synchrone, via une connexion TCP.
Mauvaises performances ESXi et ZFS - NFS
Ce qui veut dire non seulement que le moteur NFS attend que chacune des opérations d'écriture soit validée avant de procéder à la suite, mais qu'en plus, il utilise une connexion TCP, qui est très verbeuse et qui engendre de nombreuses latences.
La connexion NFS est alors un dialogue en "accordéon" : les systèmes mettent énormément de temps à attendre les acquittements TCP, et dans ces conditions, les débits ne sont pas optimaux.
C'est la méthode choisie par VMware, puisqu'elle permet de s'assurer de l'intégrité des données, au détriment des performances.
Et c'est un choix tout à fait judicieux.
Il n'en reste pas moins que le débit d'un montage NFS sera de 60 à 80 MO/s, alors que les liaisons gigabit que l'on a mis en place permettent jusqu'à environ 100 MO/s effectifs, si l'on compte les diverses encapsulations.
Si nous avons relié un hôte ESXi en agrégation de liens, avec deux cartes réseau gigabit, un montage NFS n'utilisera alors que le quart / tiers du maximum possible, qui est de l'ordre des 200 MO/s, sous certaines conditions.
Agrégation de liens
L'agrégation de liens permet avant tout de s'assurer de la redondance (failover), et ne promet pas d'équilibrer le trafic entre les cartes réseaux.
Pour qu'il y ait équilibrage de charge, il faut qu'il y ait plusieurs connexions établies sur l'agrégat.
Si nous avons un agrégat de 2 liens gigabit, et qu'à cet agrégat se connecte un équipement réseau, le débit sera d'un gigabit au maximum.
Si nous avons 2 équipements réseau qui se connectent à l'agrégat, il y aura un peu d'équilibrage de charge qui se fera.
L'agrégat dépassera peut-être le gigabit, sans arriver à 2 gigabits.
Plus nous aurons d'équipements qui vont se connecter à cet agrégat, et plus on s'approchera d'un équilibrage de charge idéal.
En somme, l'agrégation de liens permet un mauvais équilibrage de charge, et ce n'est qu'en multipliant les connexions que l'on arrivera à s'approcher du débit maximal.
Au niveau du réseau ESXi, la méthode la plus couramment utilisée est celle de la "route basée sur le hachage IP".
Cela veut dire qu'une connexion IP donnée ne passera que par une seule carte réseau !
Si nous voulons bénéficier d'un équilibrage de charge au niveau ESXi, il faut donc multiplier les connexions IP pour maximiser les débits.
Une seule solution : multiplier les points de montage NFS !
Nous avons vu qu'une connexion NFS ne permet même pas d'atteindre le maximum d'une seule carte réseau.
Et que pour maximiser les débits sur les agrégats, il fallait multiplier les connexions IP.
Il faut logiquement multiplier les montages, même pour un seul hôte ESXi.
Dans le cas de NFS, ce que je fais, c'est que je crée pour chaque machine virtuelle un point de montage différent (chaque VM utilisera donc une connexion NFS séparée), et pour bénéficier de l'équilibrage de charge, je crée une adresse IP différente pour chaque montage, sur mon serveur de stockage.
Le débit de chaque VM ne pourra séparément atteindre que les 60-80 MO/s (on n'y peut pas grand chose), mais le débit NFS cumulé de l'hôte, si les VMs sont assez nombreuses, pourra atteindre les 220 MO/s sur un agrégat 2 x 1 Gbps.
Mise en œuvre
Filer ZFS
VLANs et nouvelles IPs
Dans l'article Installation d'un serveur de fichiers ZFS sous FreeBSD, j'avais crée une aggrégation de liens entre les interfaces réseau Broadcom (intégrée) et Intel (PCI Express), en attribuant l'ip 192.168.0.3/24 à l'interface lagg0 agrégée, via le fichier /etc/rc.conf :
cloned_interfaces="lagg0"
ifconfig_bge0="up"
ifconfig_em0="up"
ifconfig_lagg0="laggproto lacp laggport bge0 laggport em0"
ipv4_addrs_lagg0="192.168.0.3/24"
Je garde l'ip 192.168.0.3 pour les besoins divers, sur le vlan par défaut.
J'ajoute l'interface lagg0 sur le VLAN3, défini pour le stockage ESXi, et j'assigne une dizaine d'alias IP, puisque nous voulons que chaque VM ait son propre montage NFS, sur une IP spécifique :
cloned_interfaces="lagg0 vlan3"
ifconfig_vlan3="vlan 3 vlandev lagg0"
ipv4_addrs_vlan3="192.168.3.130/24 192.168.3.131/24 192.168.3.132/24 192.168.3.133/24 192.168.3.134/24 192.168.3.135/24 192.168.3.136/24 192.168.3.137/24 192.168.3.138/24 192.168.3.139/24"
Pour prendre en compte les changements :
/etc/rc.d/netif restart && /etc/rc.d/routing restart
J'avais aussi crée un "export NFS", en utilisant la fonctionnalité intégrée à ZFS :
zfs set sharenfs="-mapall=mydata -alldirs -network 192.168.0.0 -mask 255.255.255.0" mydata
Maintenant, je souhaiterais y ajouter le réseau 192.168.3.0/24, que j'ai réservé pour le stockage ESXi, dans le VLAN3.
Si je rajoute la ligne suivante, je perds la connexion sur le réseau 192.168.0.0/24 !
zfs set sharenfs="-mapall=mydata -alldirs -network 192.168.0.0/24 -network 192.168.3.0/24" mydata
C'est tout simplement parce que la fonctionnalité sharenfs de ZFS n'est pas prévue pour partager un dataset sur plusieurs plages IP.
Ce n'est pas qu'il y a un inconvénient à le faire, c'est juste que la fonction sharenfs a été mal conçue, et qu'elle ne sait pas gérer correctement de multiples paramètres -network ...
2 solutions possibles :
- on abandonne l'utilisation de NFS over ZFS, qui servait d'interface "unificatrice", et on passe par les exports NFS classiques
- on garde la gestion de NFS via ZFS, et on profite d'un bug du parseur pour faire de multiples exports NFS =P
Personnellement, c'est la solution que j'ai retenu, bien qu'elle ne soit pas "propre".
J'envoie deux lignes qui seront traitées comme une seule, et ainsi, la chaîne sera insérée avec le saut de ligne originel dans le fichier /etc/zfs/exports :
zfs set sharenfs="-mapall=mydata -alldirs -network 192.168.0.0/24
/mydata -mapall=mydata -alldirs -network 192.168.3.0/24" mydata
cat /etc/zfs/exports
# !!! DO NOT EDIT THIS FILE MANUALLY !!!
/mydata -mapall=mydata -alldirs -network 192.168.0.0/24
/mydata -mapall=mydata -alldirs -network 192.168.3.0/24
Et voilà, nous avons reconfiguré le filer pour qu'il puisse délivrer ses données sur un VLAN supplémentaire, en présentant de multiples IP aux hôtes ESXi !
MTU
Là, j'ai eu ma première vraie déception avec le HP Proliant Microserver : la carte réseau intégrée Broadcom BCM5723 ne supporte pas les Jumbo Frames ...
La carte Intel elle, si, bien-sûr.
Il n'est donc pas envisageable d'activer les Jumbo Frames pour l'agrégation, puisqu'avoir un MTU de 1500 pour une carte physique et un MTU de 9000 pour l'autre peut engendrer des comportements imprévisibles !
Comme il n'y a que deux slots PCI Express sur le Microserver, et que j'ai inséré dans le plus rapide une carte contrôleur supplémentaire, il n'est de toute façon pas possible de mettre une carte réseau gigabit dual ports sur le slot PCI Express x1 restant.
Le filer va donc devoir rester avec une MTU de 1500 octets.
Je décris tout de même le paramétrage du MTU sur FreeBSD, qui est très facile, toujours via le fichier /etc/rc.conf :
ifconfig_bge0="mtu 9000"
ifconfig_em0="mtu 9000"
En changeant les MTU des interfaces physiques, le MTU des cartes virtuelles lagg0 et vlan3 s'ajustera automatiquement, c'est une propriété "héritée"
Switch Cisco SG300-10
L'interface web du switch est très bien faite, mais le shell reste LA référence pour les switches Cisco, donc je joins les commandes correspondantes.
S'assurer de la méthode employée pour l'équilibrage de charge :
port-channel load-balance src-dst-mac-ip
("IP/MAC Address", couche 3, et non pas "MAC Address", couche 2)
Créer les VLANs 2 à 4 :
interface vlan 2
name vManagement
interface vlan 3
name vStorage
interface vlan 4
name vMotion

Assigner les accès VLANs à chacune des agrégations (LAG), en plus du VLAN 1 :
interface Port-channel1
description lag_cthulhu
switchport trunk allowed vlan add 3
interface Port-channel2
description lag_vsphere
switchport trunk allowed vlan add 2-4
interface Port-channel3
description lag_seven
switchport trunk allowed vlan add 2

Cthulhu est le nom de mon serveur de fichiers, seul vStorage (et le réseau 1, par défaut) lui est accessible.
J'ai appelé le serveur ESXi vsphere, et il a naturellement accès à tous les VLANs (vStorage, mais aussi vMotion, et vManagement).
J'utilise pour contrôler vSphere un poste sous Windows Seven, il n'a accès qu'au VLAN de management.
Noter que nous assignons les VLANs non pas aux interfaces physiques, mais aux agrégations !
Activer les jumbo frames (nécessite un reboot du switch) :
port jumbo-frames

ESXi
Paramétrages NFS et IP
Par défaut, un hôte ne gère que 8 montages NFS simultanés, limite vite atteinte.
Nous allons passer à 64, et ajuster la couche TCP/IP en conséquence.
Et vérifier que les valeurs NFS "Heartbeat" restent celles recommandées par VMware.
Configuration -> Paramètres avancés
NFS.MaxVolumes 64 (maximum 256)
Net.TcpIpHeapSize 32
Net.TcpIpHeapMax 256 (maximum 512)
NFS.HeartbeatFrequency 12
NFS.HeartbeatDelta 12
NFS.HeartbeatTimeout 5
NFS.HeartbeatMaxFailures 10
Redémarrer l'hôte, et puis ajouter les différents datastores dont vous avez besoin (dans mon cas, je laisse pour le moment quelques hôtes sur le stockage local, pour des raisons de performance)

Configuration des VLANs
Nous ajoutons des interfaces pour les VLANs 2 (vManagement) et 3 (vStorage), en plus de l'interface de gestion par défaut, sur le VLAN 1.
Pour être assurés de garder la main sur la console de gestion, même en cas d'erreur de configuration, c'est une question de bon sens !
Nous vérifierons que tout marche correctement, et seulement après, nous supprimerons l'interface de gestion par défaut.
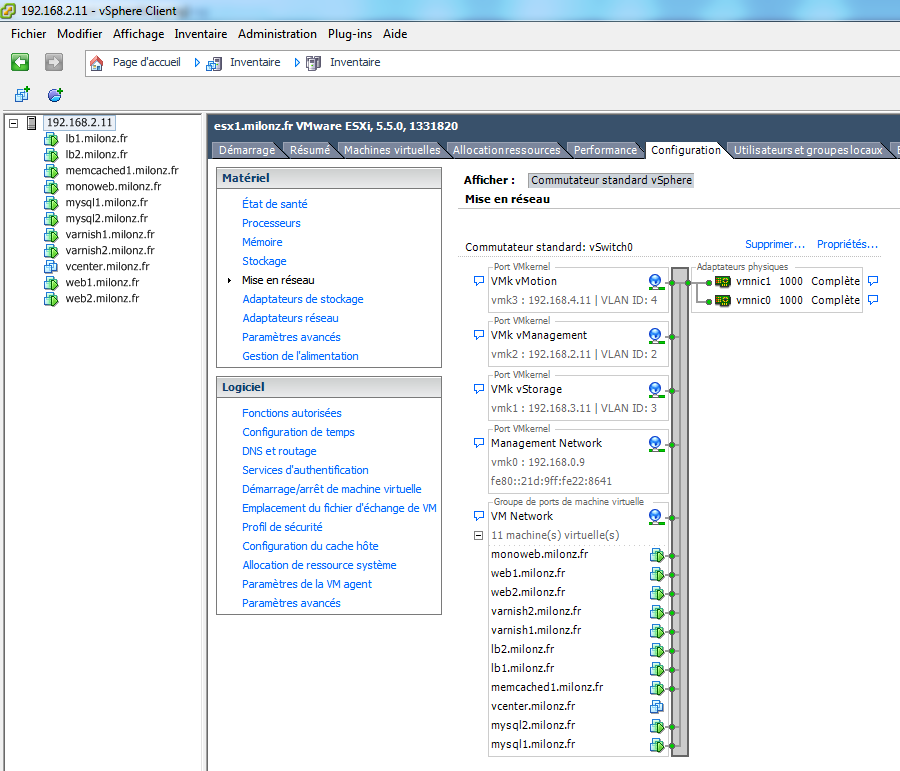
Il faut aussi bien penser aux questions de connectivité externe : mon ESX doit au minimum accéder à un serveur DNS ainsi qu'à un serveur SMTP (pour ghettoVCB entre autres).
Une nouvelle fonctionnalité de vSphere 5.X permet de télécharger directement depuis le site de VMware les dernières versions d'ESXi, il faut donc une connectivité Internet pour en bénéficier.
Pareillement si vous décidez de configurer l'envoi de mails d'alerte via vCenter.
Donc soit vous permettez l'accès à Internet depuis les hôtes ESXi (encore envisageable pour un lab, totalement proscrit pour de la production !), soit vous mettez en place des services LAN qui serviront de "tampon", et qui permettront de bénéficier des avantages, sans les inconvénients.
Par exemple un serveur DNS local, un relais mail, un proxy Squid qui filtrera les requêtes HTTP, etc.
Pour une meilleure distribution des charges, les trafics réseau administratifs sont liés à l'agrégation "vmnic0, vmnic1"
Pour le groupe de ports qui contrôle le trafic des machines virtuelles, je change l'ordre dans l'agrégation, pour "vmnic1, vmnic0"
De cette façon, c'est d'abord vmnic1 qui sera utilisée pour les VMs, c'est une façon rudimentaire d'équilibrer un peu plus la charge entre les 2 interfaces réseau.
Réseau administratif :

Réseau VMs :

Configuration du MTU
Se passe de commentaires ;-)

Benchmark du trafic NFS cumulé
iozone -i 0 -i 1 -t 1 -F iozonetest1 -r 1024 -s 1g
sur 5 machines virtuelles
J'obtiens dans les 1,3 Gbs en lecture / écriture, ce qui prouve déjà qu'il y a bien répartition de charge.
L'architecture du serveur de stockage est ici un facteur limitant pour la bande passante :
il n'a que 4 disques de 3TO, en 5400 RPM, puisque j'ai privilégié l'espace de stockage au détriment des performances, et un cache SSD L2ARC.
Il y a 5 machines virtuelles en accès simultané, et les disques ne sont pas suffisamment performants, en termes de IOPS (Input/Output Per Second).
Mais sur un datastore doté de disques plus rapides, la bande passante atteindra bien les 2 Gbps.
Conclusion
Nous avons vu dans cet article que les performances d'ESXi sont avant tout liées à l'architecture choisie, et qu'il faut y apporter un très grand soin.
Il y a bien quelques "tweaks" que l'on peut paramétrer sur les hôtes, qui sont utiles, mais qui ne sont pas "magiques" ...
Un administrateur qui gère une infrastructure virtualisée est avant tout quelqu'un avec une bonne culture générale, qui connait les "petits trucs" pour optimiser chaque niveau de l'architecture.
Et qui comprend le fonctionnement interne d'ESXi et de l'environnement vSphere, afin d'adapter l'infrastructure au logiciel, et non pas le contraire !
Partager l'article



 Milosz SZOT est ingénieur systèmes & réseaux spécialisé dans Linux et l'hébergement de sites web à fort trafic.
Milosz SZOT est ingénieur systèmes & réseaux spécialisé dans Linux et l'hébergement de sites web à fort trafic.